分布式数据库名词解释,跨越地域界限的数据管理新篇章
分布式数据库(Distributed Database)是一种数据库架构,它将数据分布在多个物理位置上,这些物理位置可以是不同的服务器、不同的地理位置,甚至不同的网络。这种架构的主要目的是提高数据处理的效率、可靠性和可扩展性。
以下是分布式数据库的一些关键概念和术语:
1. 节点(Node):分布式数据库中的每个物理位置都称为一个节点。每个节点可以包含一部分数据,并且可以独立处理数据请求。
2. 数据分片(Data Sharding):将数据按照某种规则分散到不同的节点上,以便提高数据访问的效率和负载均衡。
3. 复制(Replication):为了提高数据的可靠性和可用性,分布式数据库通常会复制数据到多个节点上。复制可以是同步的,也可以是异步的。
4. 一致性(Consistency):在分布式数据库中,一致性是指所有节点上的数据副本都是最新的,并且保持一致的状态。
5. 分区(Partitioning):将数据划分为多个逻辑部分,每个部分称为一个分区。分区可以基于数据的关键字、范围或其他规则进行划分。
6. 故障转移(Failover):当某个节点发生故障时,分布式数据库可以自动将故障节点的数据请求转移到其他节点上,以保证服务的连续性。
7. 负载均衡(Load Balancing):通过将数据请求分散到不同的节点上,分布式数据库可以平衡各个节点的负载,提高整体性能。
8. 分布式事务(Distributed Transaction):在分布式数据库中,一个事务可能涉及多个节点上的数据操作。分布式事务需要保证事务的原子性、一致性、隔离性和持久性(ACID属性)。
9. CAP定理(CAP Theorem):CAP定理指出,一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)中的两个。这一定理是分布式数据库设计和实现时需要考虑的重要因素。
10. 副本一致性(Replica Consistency):在分布式数据库中,由于数据可能被复制到多个节点上,副本一致性是指所有数据副本都保持一致的状态。副本一致性可以通过不同的复制策略和一致性协议来实现。
11. 分布式查询(Distributed Query):在分布式数据库中,一个查询可能需要访问多个节点上的数据。分布式查询需要处理数据的分布、数据的传输和数据的合并等复杂问题。
12. 分布式锁(Distributed Lock):在分布式数据库中,为了防止多个节点同时修改同一数据,需要使用分布式锁来保证数据的一致性。
13. 分布式缓存(Distributed Cache):为了提高数据访问的效率和减少对数据库的访问压力,分布式数据库通常会使用分布式缓存来缓存热点数据。
14. 分布式索引(Distributed Index):在分布式数据库中,索引也可能被分布在多个节点上。分布式索引需要处理索引的创建、维护和查询等复杂问题。
15. 分布式监控(Distributed Monitoring):为了确保分布式数据库的稳定运行,需要对其进行实时监控。分布式监控需要收集和分析来自各个节点的监控数据。
16. 分布式备份(Distributed Backup):为了提高数据的可靠性,分布式数据库需要进行数据备份。分布式备份需要考虑数据的分布、备份的效率和恢复的可行性等问题。
17. 分布式安全(Distributed Security):分布式数据库需要考虑数据的安全性和隐私性。分布式安全包括数据的加密、访问控制、审计和入侵检测等方面。
18. 分布式调度(Distributed Scheduling):在分布式数据库中,需要合理地调度各个节点的资源,以提高整体性能。分布式调度需要考虑任务的分配、执行和优化等问题。
19. 分布式优化(Distributed Optimization):为了提高分布式数据库的性能,需要进行分布式优化。分布式优化包括查询优化、索引优化、缓存优化等方面。
20. 分布式协议(Distributed Protocol):分布式数据库需要使用各种协议来保证数据的分布、复制、一致性和安全性。常见的分布式协议包括Paxos、Raft、Zab等。亲爱的读者们,你是否曾好奇过,那些庞大的互联网公司是如何管理海量数据的?今天,就让我带你走进神秘的分布式数据库世界,揭开它的神秘面纱!
什么是分布式数据库?
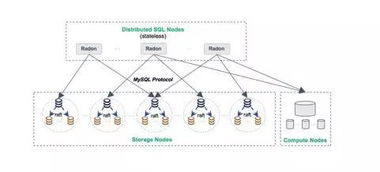
想象你手中有一把钥匙,可以打开无数把锁。分布式数据库就是这样一个神奇的工具,它可以将数据分散存储在多个服务器上,而你只需通过这把“钥匙”,就能轻松访问这些分散的数据。
简单来说,分布式数据库就是将数据存储在多个地理位置不同的服务器上,通过计算机网络连接起来,形成一个统一的数据库系统。这样做的目的是为了提高数据存储的可靠性、扩展性和性能。
分布式数据库的优势
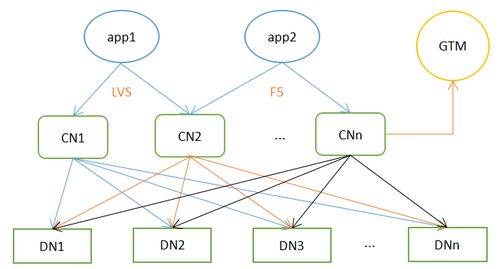
1. 高可靠性:当一台服务器出现故障时,其他服务器仍然可以正常工作,确保数据的安全性和可用性。
2. 高性能:分布式数据库可以将数据分散存储在多个服务器上,从而提高数据访问速度和查询效率。
3. 可扩展性:随着业务的发展,分布式数据库可以轻松扩展,满足不断增长的数据存储需求。
分布式数据库的组成
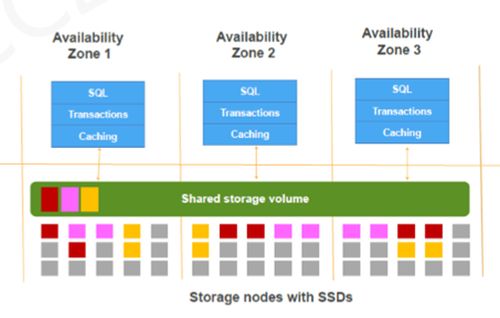
分布式数据库由以下几个部分组成:
1. 数据节点:负责存储数据的物理服务器。
2. 网络:连接各个数据节点的通信网络。
3. 数据库管理系统:负责管理数据节点、网络和数据库的软件系统。
4. 应用层:通过数据库管理系统访问数据库的应用程序。
分布式数据库的应用场景
1. 大型互联网公司:如阿里巴巴、腾讯、百度等,它们需要处理海量数据,分布式数据库可以帮助它们提高数据存储和处理能力。
2. 金融行业:分布式数据库可以提高金融交易的实时性和可靠性。
3. 物联网:分布式数据库可以存储和管理大量物联网设备产生的数据。
分布式数据库的挑战
1. 数据一致性:如何保证分布式数据库中各个数据节点的数据一致性是一个难题。
2. 数据分区:如何将数据合理地分配到各个数据节点,是一个需要考虑的问题。
3. 网络延迟:网络延迟可能会影响分布式数据库的性能。
分布式数据库的未来
随着云计算、大数据和人工智能等技术的发展,分布式数据库将会在更多领域得到应用。未来,分布式数据库将会更加智能化、自动化,为人们的生活带来更多便利。
分布式数据库是一个充满魅力的领域,它为人们带来了前所未有的数据存储和处理能力。让我们一起期待,分布式数据库在未来会带给我们更多惊喜!
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:admin@admin.com